一、介绍及用处
Selenium是一个开源的Web UI自动化测试工具,可以用于测试浏览器和移动设备,它支持多种编程语言,和页面爬虫差不多,页面爬虫主要是获取页面元素,自动化主要是对页面元素模拟点击输入等操作,所以说学会ui自动化后学爬虫就非常简单了。
优点:ui自动化方便项目的回归测试,也可以对经常重复性的操作进行自动化,省去枯燥无谓的操作。
缺点:就是维护成本高,UI自动化搞不好会适得其反,浪费了大量的时间和资源去排查环境的问题。
二、环境安装
- 首先下载python,进行安装。
- 选择自己的编译器,这里使用pycharm,选择点击下载,选择左边免费版下载就行,然后进行安装。
- win + R键输入cmd,在命令窗口输入python,出现版本号,配置成功。

- (这一步可操作可不操作)改成中文,打开pycharm,选择Plugins,在输入框里输入Chinese,点击下载即可
- 点击New Project,点击ok
- 找到 file(文件)——settings(设置)——Project(项目)——Python interpreter(Python解释器)——Add interpreter(添加解释器)——System interpret(系统解释器)路径找到自己安装的Python.exe目录,默认目录(C:\Users\用户名称\AppData\Local\Programs\Python\Python版本号),选择python.exe,点击OK,点击Apply(应用)即可。
- 下载webdriver,和自己Chrome(谷歌)浏览器版本对应的驱动,如果没有那就下载包含版本数字最多的,其他浏览器也是一样的操作。[webdriver下载地址2需要链接外网访问][https://googlechromelabs.github.io/chrome-for-testing/]
- 下载后配置环境变量,添加到系统环境变量path中,值为你存放的目录,接下来cmd输入:webdriver,回车,跳出浏览器即可。(还有一种简单方法,直接把webdriver放入python.exe的目录,此方法不用在cmd中验证)
- 在pycharm中找到 file(文件)——settings(设置)——Project(项目)——Python interpreter(Python解释器)——“+”号,点击后输入selenium,点击install(下载)即可。
- 删除新建项目main中的内容输入
# 导入webdriver from selenium import webdriver # 导入时间 import time # 实例化 driver = webdriver.Chrome() # 打开百度网页 driver.get("https://www.baidu.com/") # 等待三秒 time.sleep(3) # 关闭浏览器 driver.quit() - 鼠标右键,选择run.main,即可自动打开浏览器,进入百度页面,然后关闭。
三、定位元素及操作
3.1定位元素
我们主要用到id,name,xpath,link_text进行定位。webdrive有八个定位元素操作:
| 名称 | 方式 | 解释 |
|---|---|---|
| id | find_element_by_id(x) | id必须唯一,通过id进行定位 |
| name | find_element_by_name(x) | 如果没有id,可以通过name进行定位,name必须唯一 |
| xpath | find_element_by_xpath(x) | 层级进行定位 |
| link_tex | find_element_by_link_text(x) | 文本进行定位 |
| partial_link_text | find_element_by_partial_link_text(x) | 模糊定位 |
| tag_name | find_element_by_tag_name(x) | 标签名字定位 |
| class_name | find_element_by_class_name(x) | 类名定位 |
| css_selector | find_element_by_css_selector(x) | css定位 |
3.2鼠标键盘操作
如果以下操作输入后没有提示的则需要前面导入键盘鼠标操作ActionChains(from selenium.webdriver.common.action_chains import ActionChains)
- 点击元素:driver.find_element_by_id(“someid”).click()
这个方法可以点击传入的元素。 - 在元素上双击:driver.find_element_by_id(“someid”).double_click()
这个方法可以在传入的元素上双击。 - 右键点击元素:driver.find_element_by_id(“someid”).context_click()
这个方法可以在元素上右键点击。 - 模拟按键:driver.find_element_by_id(“someid”).send_keys(“some text”)
这个方法可以模拟按键输入文本,可以传入字符串、键盘按键代码、上传文件等。 - 清除输入框内容:driver.find_element_by_id(“someid”).clear()
这个方法可以清除输入框中已有的内容。 - 模拟按下某个键:driver.find_element_by_id(“someid”).send_keys(Keys.SPACE)
Keys是一个包含各种键盘按键的常量类,模拟按下某个键。 - 鼠标悬停:driver.find_element_by_id(“someid”).move_to_element()
这个方法可以模拟鼠标悬停到某个元素上。 - 拖动元素:driver.find_element_by_id(“someid”).drag_and_drop_by_offset(x, y)
这个方法可以拖动某个元素到指定的x和y偏移位置。 - 鼠标滚轮:driver.execute_script(“window.scrollTo(0, 1000);”)
这个方法可以来模拟鼠标滚轮操作,滚动到指定位置。
3.3浏览器操作
以下是基本操作,其它操作可以进行百度
- 弹出框处理
可以使用switch_to.alert来处理弹出框,并使用text、accept()、dismiss()等方法操作弹出框。 - 窗口切换
可以使用switch_to.window来切换窗口,以进行跨窗口测试。 - 截图
可以使用get_screenshot_as_png()来截取当前网页屏幕截图。 - 前进/后退
可以使用forward()和back()方法在网页间前进和后退。 - 窗口最大化
可以使用maximize_window()方法。 - 关闭浏览器
通过quit.()方法关闭浏览器
3.4代码示例
# 导入selenium
from selenium import webdriver
# Selenium中的一个工具类,它包含了许多查找元素的方法。
from selenium.webdriver.common.by import By
# 实例化
driver=webdriver.Chrome()
# 打开百度
driver.get('http://www.baidu.com')
# 窗口最大化
driver.maximize_window()
# 输入selenium
driver.find_element(By.ID,'kw').send_keys('selenium')
# 点击搜索
driver.find_element(By.ID,'su').click()
# 关闭浏览器
driver.quit()四、定位不到元素踩坑
- 首先确定元素的正确性,没问题,换种定位方法
- 页面加载慢,元素没有加载出来,需要在前面加上强制等待time.sleep(秒数)
- 看看是否有ifrome嵌套页面需要进入嵌套页面:
driver.switch_to.frame(0) 通过索引进入(可能有多个嵌套网页) - 是否为select查询,通过select查询方法:select_by_index()
- 是否为alert弹窗
- 是否为动态元素,在父元素定位后再找子元素。
- 定位下一级时,上一级是否定位到
常规踩坑大概就是这些。
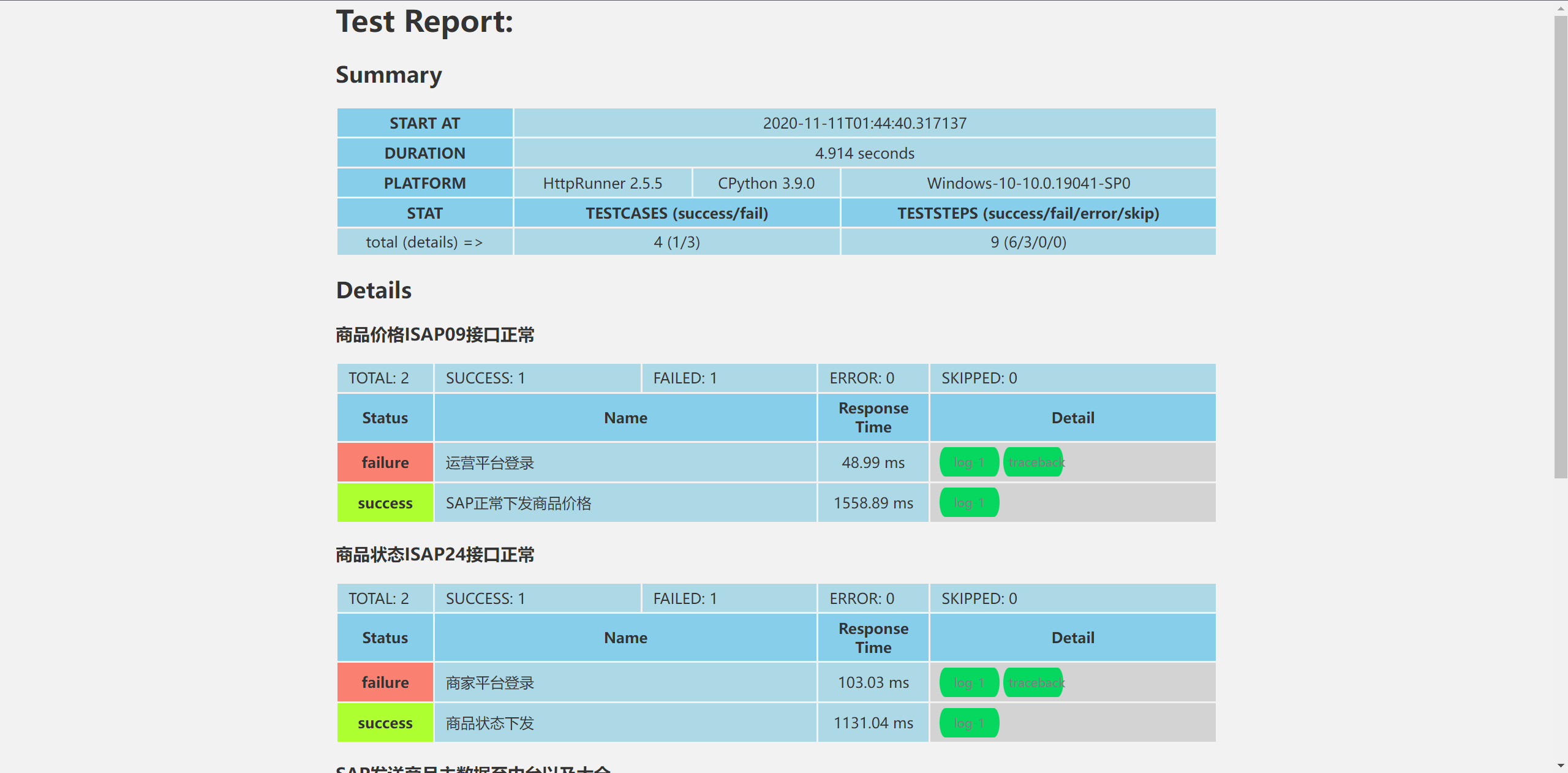
五 、使用selenium+pytest+alluer输出结果报告
- 安装pytest
pip install pytest - 安装allure-pytest
pip install allure-pytest - 下载alluer
下载地址:https://repo.maven.apache.org/maven2/io/qameta/allure/allure-commandline/
下载解压,然后把bin目录添加到系统环境变量中的path,然后cmd输入allure –version,如果出现版本号则配置成功。5.1 代码示例:
- 生成的html文件不能直接打开文件,需要使用命令行打开
(1)首先pycharm执行使用pytest运行python文件
(2)然后在pycharm执行把输出的测试结果进行生成测试报告pytest 你的文件名.py --alluredir ./allure-results
(3)在pycharm中右键选择浏览器打开allure generate ./allure-results -o ./allure-report --clean
# 导入包
import os
import time
import pytest
import allure
import subprocess
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
# 设置 Allure 报告目录
REPORT_DIR = os.path.abspath("./allure-results")
REPORT_OUTPUT_DIR = os.path.abspath("./allure-report")
# 此处为设置的用例名称和操作
@allure.feature("百度搜索")
@allure.story("搜索 Selenium 关键词")
# 开始访问百度并搜索
def test_baidu_search():
# allure.step为每个步骤的名字
with allure.step("打开浏览器并访问百度"):
# 实例化
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.maximize_window()
# 元素定位进行操作
with allure.step("输入搜索关键词并执行搜索"):
search_box = driver.find_element(By.NAME, "wd")
search_box.send_keys("Selenium")
search_box.send_keys(Keys.RETURN)
time.sleep(2) # 等待搜索结果加载
# 结果验证
with allure.step("验证搜索结果"):
assert "Selenium" in driver.title, "百度搜索结果页标题应包含 'Selenium'"
with allure.step("截图保存到 Allure 报告"):
# 截图
screenshot_path = os.path.join(REPORT_DIR, "screenshot.png")
driver.save_screenshot(screenshot_path)
allure.attach.file(screenshot_path, name="搜索结果截图", attachment_type=allure.attachment_type.PNG)
driver.quit()
# 生成的测试数据后,无法生成测试报告,不晓得为啥还是直接执行命令吧,不影响
# def run_tests():
# """ 自动执行 pytest 并生成 Allure 报告 """
# print("开始运行 UI 自动化测试...")
# # 运行 pytest 并生成测试结果数据
# subprocess.run(["pytest", "ui.py", "--alluredir", REPORT_DIR])
# print("测试执行完毕,开始生成 Allure 报告...")
# # 生成测试报告
# subprocess.run(["allure", "generate", REPORT_DIR, "-o", REPORT_OUTPUT_DIR, "--clean"])
# print(f"Allure 报告已生成,可在 '{REPORT_OUTPUT_DIR}' 目录中查看")
# if __name__ == "__main__":
# run_tests()写在最后
个人自动化脚本不用太在意这些话,主要对项目的自动化测试脚本
写法都大差不差,无非就是方法的封装和框架,框架主要是:公用方法,元素存放,配置,测试用例,结果验证,报告存放,文件存放,启动器。接手别人的自动化脚本时先定位框架里面的这几个的位置能够快速的理解别人的自动化脚本。